Note
Click here to download the full example code
GroupLasso as a transformer¶
A sample script to demonstrate how the group lasso estimators can be used for variable selection in a scikit-learn pipeline.
Setup¶
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import Ridge
from sklearn.metrics import r2_score
from sklearn.pipeline import Pipeline
from group_lasso import GroupLasso
np.random.seed(0)
Set dataset parameters¶
group_sizes = [np.random.randint(10, 20) for i in range(50)]
active_groups = [np.random.randint(2) for _ in group_sizes]
groups = np.concatenate(
[size * [i] for i, size in enumerate(group_sizes)]
).reshape(-1, 1)
num_coeffs = sum(group_sizes)
num_datapoints = 10000
noise_std = 20
Generate data matrix¶
X = np.random.standard_normal((num_datapoints, num_coeffs))
Generate coefficients¶
w = np.concatenate(
[
np.random.standard_normal(group_size) * is_active
for group_size, is_active in zip(group_sizes, active_groups)
]
)
w = w.reshape(-1, 1)
true_coefficient_mask = w != 0
intercept = 2
Generate regression targets¶
y_true = X @ w + intercept
y = y_true + np.random.randn(*y_true.shape) * noise_std
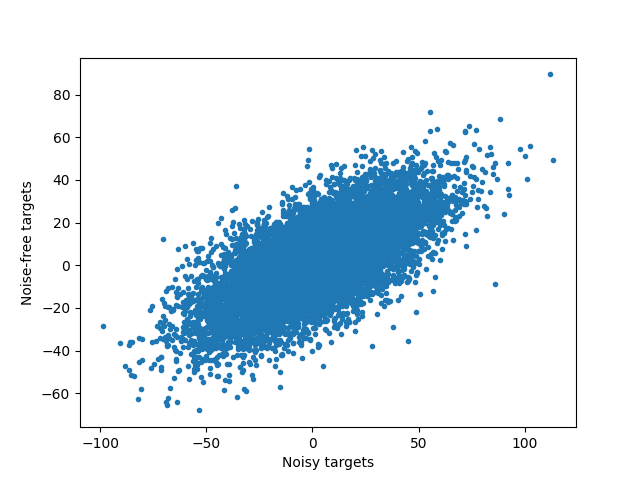
View noisy data and compute maximum R^2¶
plt.figure()
plt.plot(y, y_true, ".")
plt.xlabel("Noisy targets")
plt.ylabel("Noise-free targets")
# Use noisy y as true because that is what we would have access
# to in a real-life setting.
R2_best = r2_score(y, y_true)
Generate pipeline and train it¶
pipe = Pipeline(
memory=None,
steps=[
(
"variable_selection",
GroupLasso(
groups=groups,
group_reg=5,
l1_reg=0,
scale_reg="inverse_group_size",
subsampling_scheme=1,
supress_warning=True,
),
),
("regressor", Ridge(alpha=0.1)),
],
)
pipe.fit(X, y)
Out:
/home/docs/checkouts/readthedocs.org/user_builds/group-lasso/envs/latest/lib/python3.7/site-packages/group_lasso-1.5.0-py3.7.egg/group_lasso/_fista.py:119: ConvergenceWarning: The FISTA iterations did not converge to a sufficient minimum.
You used subsampling then this is expected, otherwise, try increasing the number of iterations or decreasing the tolerance.
Pipeline(steps=[('variable_selection',
GroupLasso(group_reg=5,
groups=array([[ 0],
[ 0],
[ 0],
[ 0],
[ 0],
[ 0],
[ 0],
[ 0],
[ 0],
[ 0],
[ 0],
[ 0],
[ 0],
[ 0],
[ 0],
[ 1],
[ 1],
[ 1],
[ 1],
[ 1],
[ 1],
[ 1],
[ 1],
[ 1],
[ 1],
[ 2],
[ 2],
[ 2],
[ 2],
[ 2],
[ 2],
[ 2],
[ 2],
[ 2],
[ 2],
[ 2],
[ 2],
[ 2],
[ 3],
[ 3],
[ 3],
[ 3],
[ 3],
[ 3],
[ 3],
[ 3],
[ 3],
[ 3],
[ 3],
[ 3],
[ 3],
[ 4],
[ 4],
[ 4],
[ 4],
[ 4],
[ 4],
[ 4],
[ 4],
[ 4],
[ 4],
[ 4],
[ 4],
[ 4],
[ 4],
[ 4],
[ 4],
[ 4],
[ 5]...
[46],
[46],
[46],
[46],
[46],
[46],
[46],
[46],
[47],
[47],
[47],
[47],
[47],
[47],
[47],
[47],
[47],
[47],
[47],
[47],
[47],
[47],
[47],
[47],
[47],
[48],
[48],
[48],
[48],
[48],
[48],
[48],
[48],
[48],
[48],
[48],
[48],
[49],
[49],
[49],
[49],
[49],
[49],
[49],
[49],
[49],
[49]]),
l1_reg=0, scale_reg='inverse_group_size',
subsampling_scheme=1, supress_warning=True)),
('regressor', Ridge(alpha=0.1))])
Extract results and compute performance metrics¶
# Extract from pipeline
yhat = pipe.predict(X)
sparsity_mask = pipe["variable_selection"].sparsity_mask_
coef = pipe["regressor"].coef_.T
# Construct full coefficient vector
w_hat = np.zeros_like(w)
w_hat[sparsity_mask] = coef
R2 = r2_score(y, yhat)
# Print performance metrics
print(f"Number variables: {len(sparsity_mask)}")
print(f"Number of chosen variables: {sparsity_mask.sum()}")
print(f"R^2: {R2}, best possible R^2 = {R2_best}")
Out:
Number variables: 720
Number of chosen variables: 313
R^2: 0.46373947136901283, best possible R^2 = 0.46262785225190173
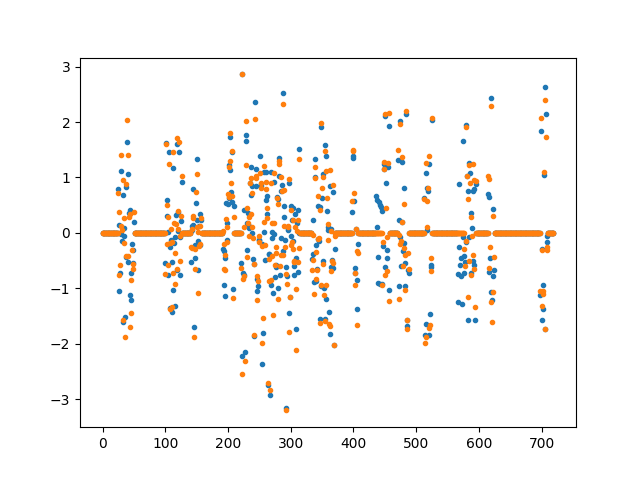
Visualise regression coefficients¶
for i in range(w.shape[1]):
plt.figure()
plt.plot(w[:, i], ".", label="True weights")
plt.plot(w_hat[:, i], ".", label="Estimated weights")
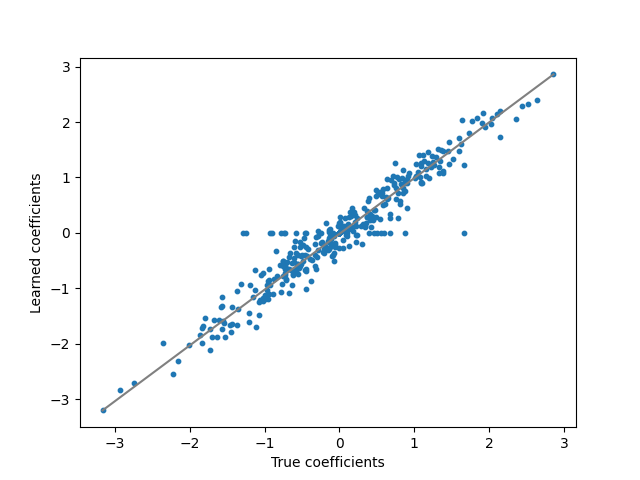
plt.figure()
plt.plot([w.min(), w.max()], [coef.min(), coef.max()], "gray")
plt.scatter(w, w_hat, s=10)
plt.ylabel("Learned coefficients")
plt.xlabel("True coefficients")
plt.show()
Total running time of the script: ( 0 minutes 4.421 seconds)